SLI — Индикаторы уровня сервиса
На этой странице описано, какие индикаторы уровня сервиса (SLI) мы используем для клиентских проектов, как именно их измеряем и где проходят границы этих измерений. Мы публикуем эту информацию, чтобы клиент мог понять не только целевые показатели, но и методику, ограничения и порядок интерпретации метрик.
Эта страница носит описательный характер. Приведённые значения SLI и SLO являются типовыми ориентирами для проектов на поддержке и не заменяют индивидуальные условия, зафиксированные в договоре, SOW и SLA.
Как читать эту страницу
Зачем бизнесу SLI
SLI, SLO, SLA — как они связаны
Что мы измеряем.
Числовые показатели, отражающие реальный пользовательский опыт: доступность, скорость отклика, процент ошибок, Core Web Vitals. SLI — это факт, зафиксированный инструментами мониторинга, а не субъективная оценка.К чему мы стремимся.
Внутренние целевые планки для каждого SLI. Например: «время отклика API — не более 300 мс для 95 % запросов». SLO задаёт планку качества, которую мы контролируем ежедневно и пересматриваем ежеквартально.Что мы гарантируем.
Формальные обязательства, закреплённые в договоре. Если SLO — это наш внутренний стандарт, то SLA — это обещание клиенту с ответственностью за его нарушение. Подробнее о нашем SLAПринцип: SLI питают SLO, SLO формируют SLA. Без достоверных индикаторов любые гарантии — пустые слова. Поэтому мы начинаем с измерений.
Что мы измеряем
Основные индикаторы
| Индикатор | Что показывает | Как считаем | Ориентир (SLO) |
|---|---|---|---|
| Uptime (Доступность) | Доля времени, когда сервис доступен и отвечает корректно | Доля успешных HTTP-ответов (2xx/3xx) от общего числа синтетических проверок | ≥ 99,5 % (стандарт), ≥ 99,8 % (цель) |
| Latency (Время отклика) | Скорость ответа сервера на запрос пользователя | Перцентили P50, P95, P99 по всем запросам за период | P95 < 300 мс (API), P95 < 2 с (страница) |
| Error Rate (Уровень ошибок) | Доля запросов, завершившихся серверной ошибкой | Процент ответов 5xx от общего числа запросов | < 0,1 % |
| First Response Time | Как быстро команда реагирует на поступивший тикет | Время от создания тикета до первого содержательного ответа | ≤ 20 мин (S1, рабочие часы) |
Core Web Vitals
| Метрика | Что измеряет | Порог «хорошо» | Наш инструмент |
|---|---|---|---|
| LCP (Largest Contentful Paint) | Скорость загрузки основного контента страницы | ≤ 2,5 с | Lighthouse CI |
| INP (Interaction to Next Paint) | Отзывчивость страницы на действия пользователя | ≤ 200 мс | Lighthouse CI |
| CLS (Cumulative Layout Shift) | Визуальная стабильность — отсутствие «прыжков» элементов | ≤ 0,1 | Lighthouse CI |
Дополнительные индикаторы
| Индикатор | Что показывает | Ориентир (SLO) |
|---|---|---|
| TTMR (Time to Mitigation/Restore) | Время от начала инцидента до восстановления работоспособности | ≤ 4 ч (S1), ≤ 8 ч (S2) |
| Deployment Success Rate | Доля деплоев, не приведших к деградации сервиса | ≥ 99 % |
| Saturation (Насыщенность) | Загрузка серверных ресурсов: CPU, RAM, диск | CPU idle > 10 %, RAM < 85 %, диск > 10 % свободно |
| SSL/Domain Expiry | Контроль сроков действия сертификатов и доменов | Оповещение за ≥ 30 дней до истечения |
Значения в таблицах выше приведены как базовые ориентиры. Для конкретного проекта они уточняются после онбординга, анализа архитектуры, профиля нагрузки и критичности бизнес-процессов.
Как мы измеряем: инструменты и методология
UptimeRobot — внешний мониторинг доступности
Синтетические проверки с нескольких географических точек каждые 1–5 минут:
- HTTP/HTTPS, Ping, порт-проверки, DNS и SSL-мониторинг
- Мгновенные оповещения при недоступности через email, Slack, Telegram
- Исторические данные uptime для отчётности
- Публичные status-страницы для прозрачности перед пользователями
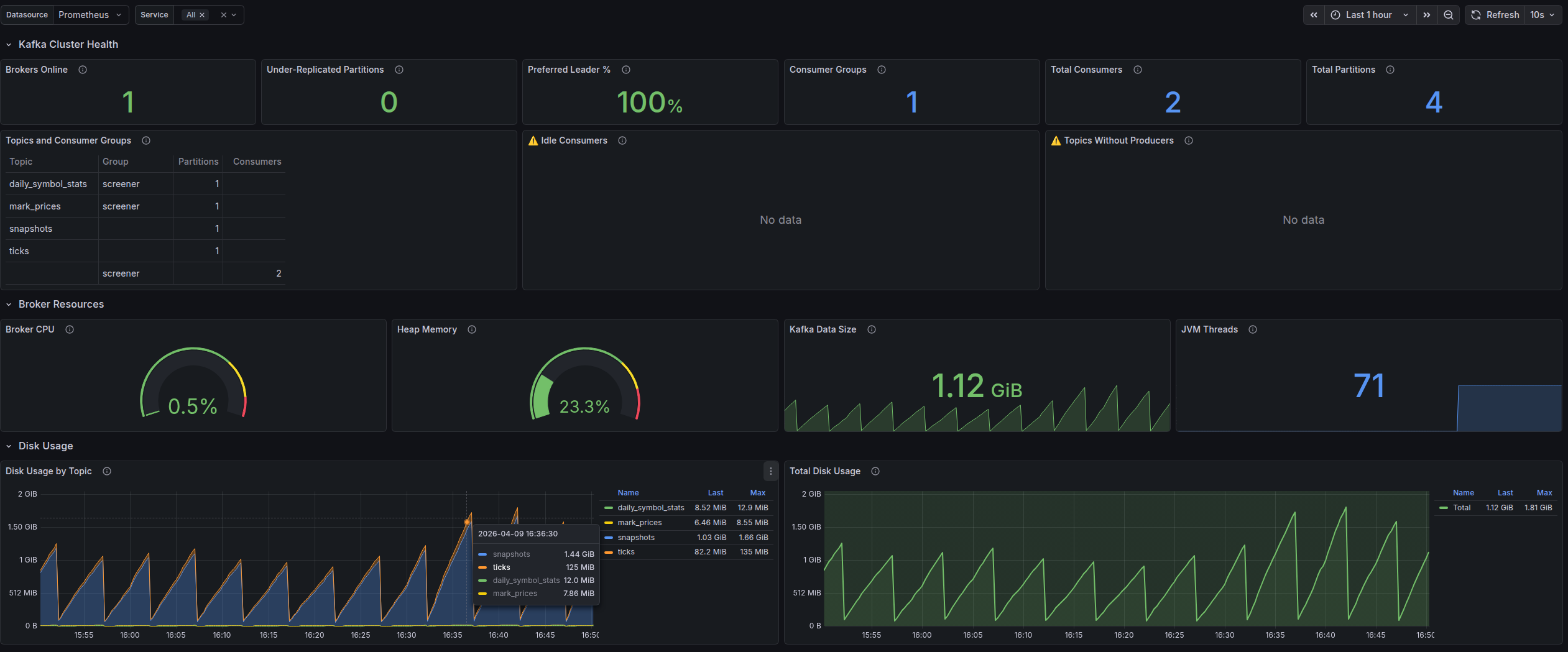
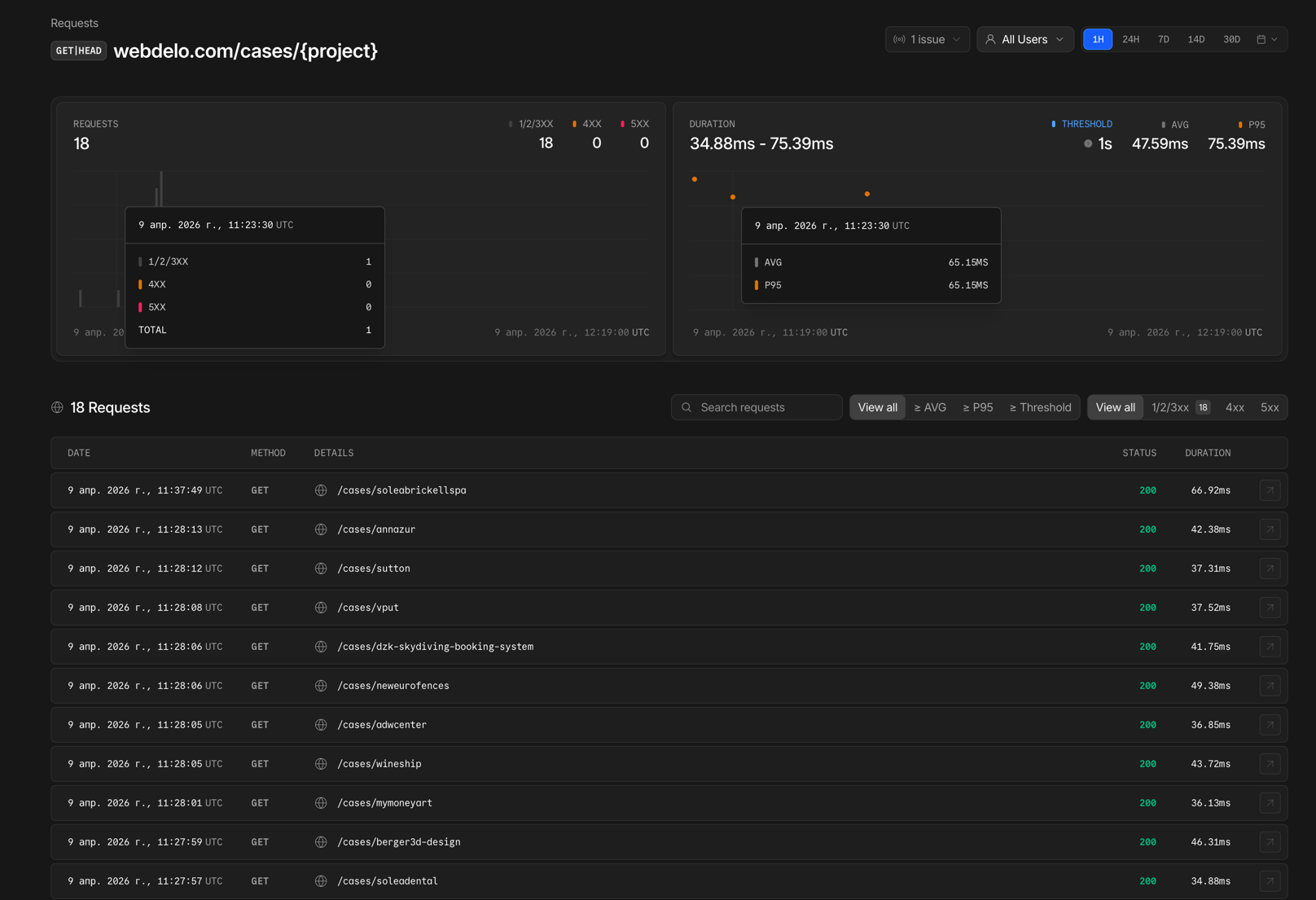
Grafana + Prometheus — визуализация и аналитика
Prometheus собирает метрики с серверов и приложений, Grafana визуализирует их на настраиваемых дашбордах:
- Latency (P50, P95, P99), error rate, throughput — в реальном времени
- Мониторинг серверных ресурсов: CPU, RAM, диск, сеть
- Настраиваемые алерты при превышении пороговых значений
- Исторические тренды для выявления деградации до того, как она станет инцидентом
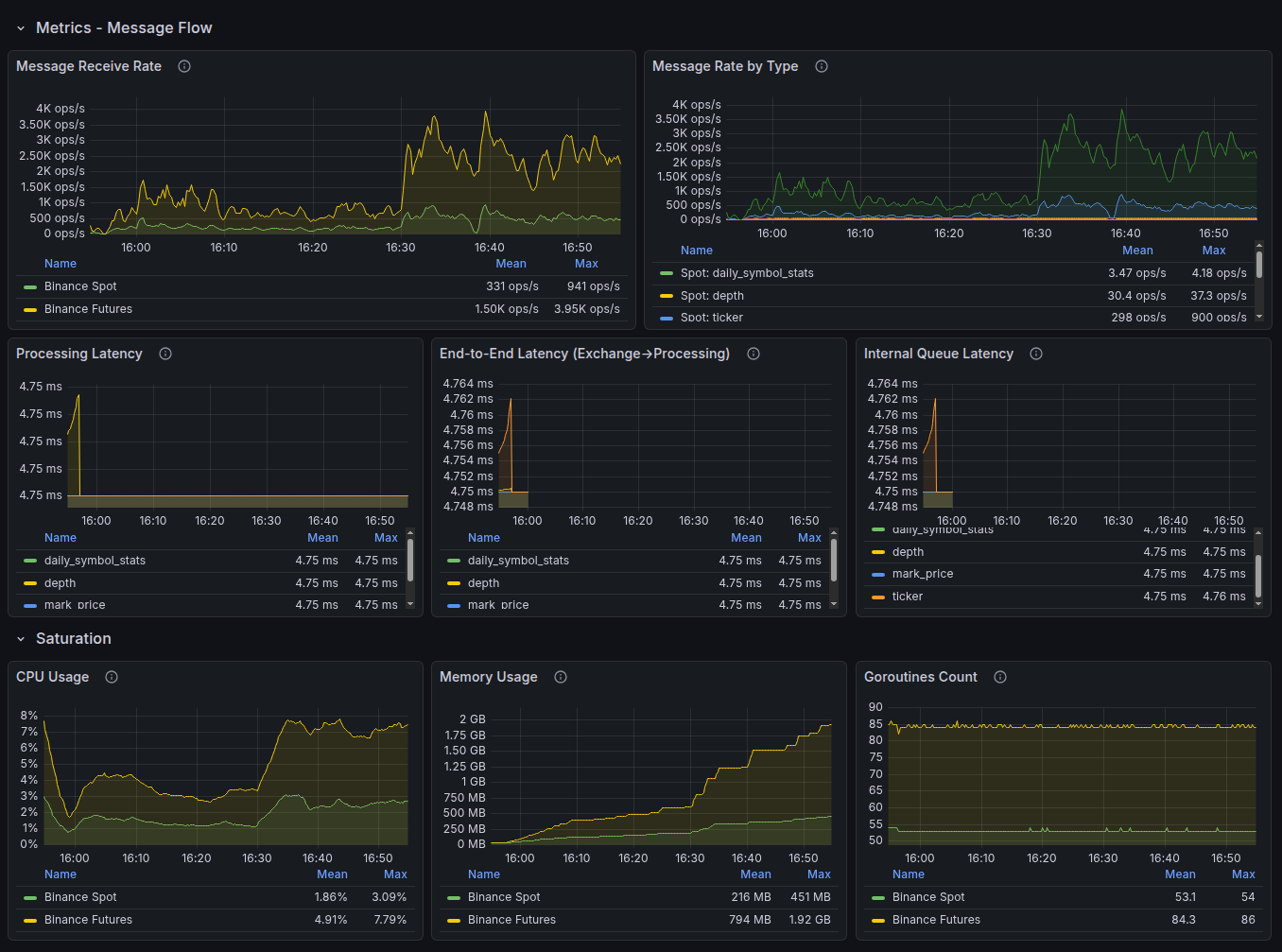
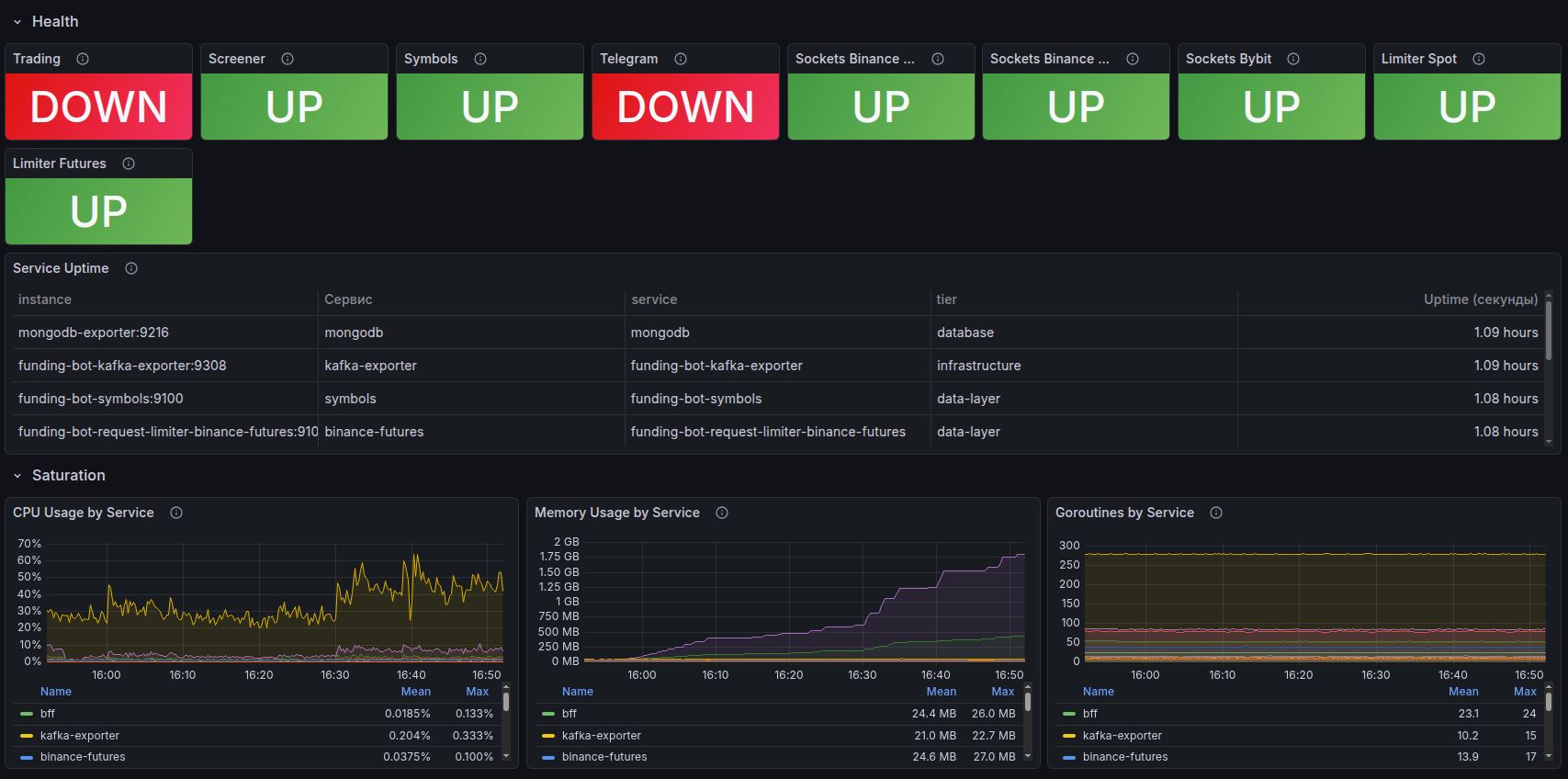
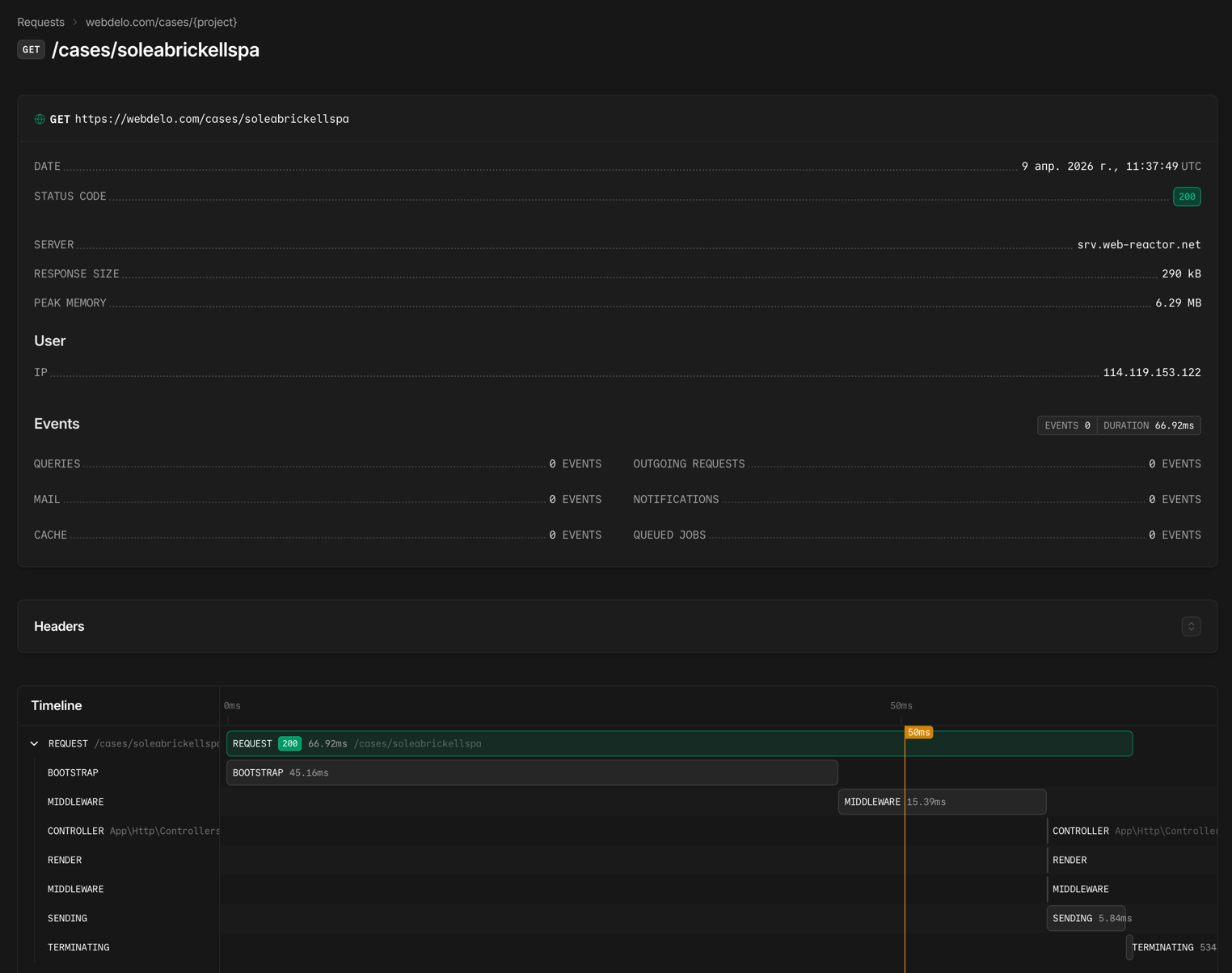
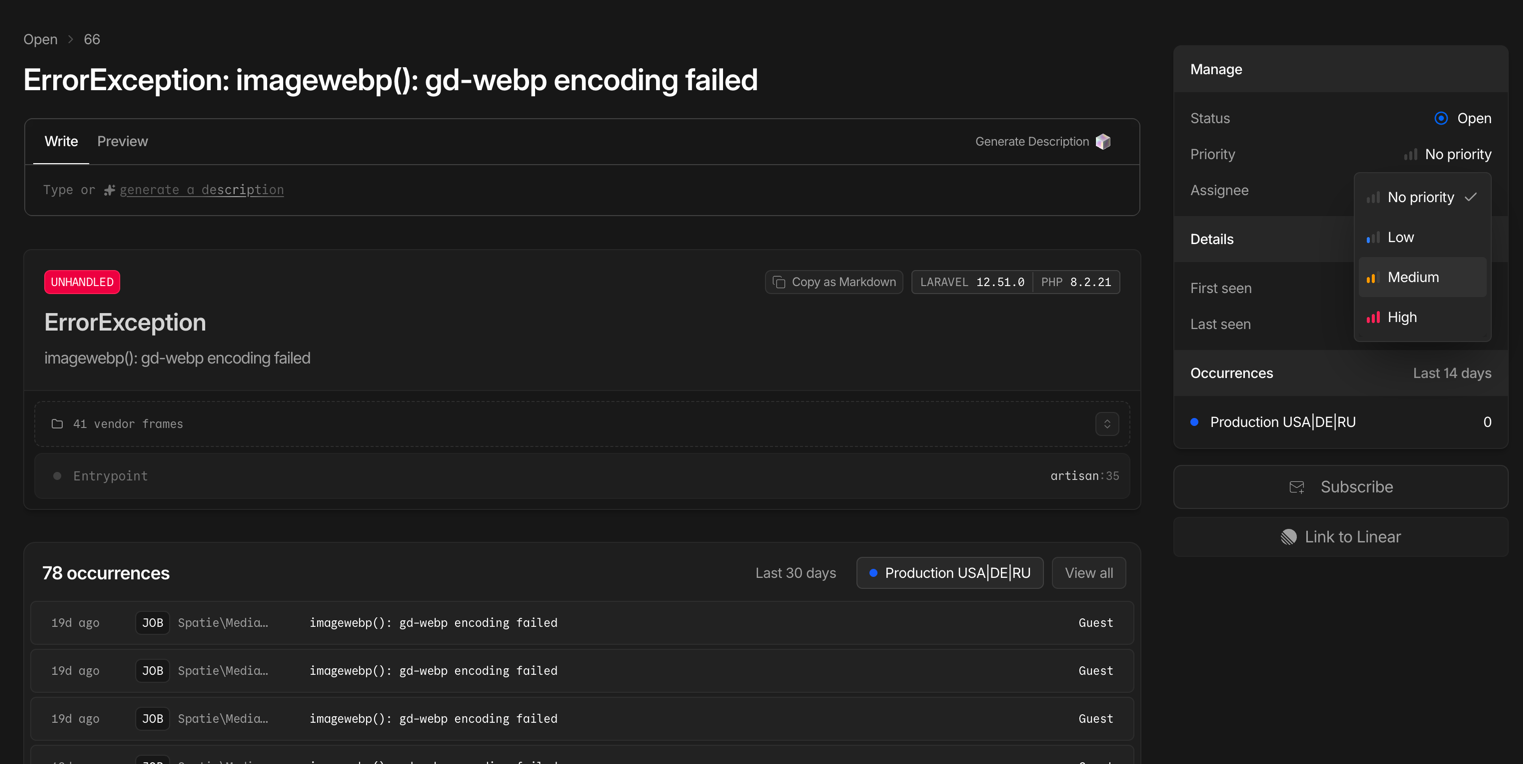
Laravel Nightwatch — мониторинг на уровне приложения
Глубокая инструментация Laravel-приложений от создателей фреймворка:
- Трассировка каждого запроса от входа до ответа
- Выявление медленных SQL-запросов и узких мест в очередях
- Мониторинг исключений и ошибок в реальном времени
- Контроль выполнения фоновых задач и cron-расписания
Примечание: На отдельных проектах в качестве альтернативы Nightwatch используется New Relic APM — полнофункциональная платформа мониторинга производительности. Выбор инструмента определяется архитектурой проекта и требованиями клиента.
Lighthouse CI — контроль Core Web Vitals
Автоматический аудит производительности при каждом деплое:
- Запуск в CI/CD-пайплайне Bitbucket Pipelines
- Сравнение метрик с предыдущим релизом — регрессии видны сразу
- LCP, INP, CLS, а также аудит доступности и SEO
- Блокировка деплоя при критическом ухудшении показателей
Методология
Error Budget — бюджет допустимых ошибок
| Целевой Uptime | Допустимый простой в месяц | Допустимый простой в год |
|---|---|---|
| 99,5 % | ~3 ч 39 мин | ~43 ч 48 мин |
| 99,8 % | ~1 ч 27 мин | ~17 ч 31 мин |
| 99,9 % | ~43 мин | ~8 ч 46 мин |
| 99,95 % | ~22 мин | ~4 ч 23 мин |
Почему это важно для вас: Error Budget помогает нам принимать решения не на основе эмоций («давайте ничего не трогать»), а на основе данных. Это означает, что ваш проект развивается максимально быстро при заданном уровне надёжности.
Уровни мониторинга по планам поддержки
| Возможность | Basic | Extended | Enterprise |
|---|---|---|---|
| Синтетические проверки доступности (Uptime) | ✓ | ✓ | ✓ |
| Контроль SSL-сертификатов и доменов | ✓ | ✓ | ✓ |
| Оповещения при недоступности | ✓ | ✓ | ✓ |
| Lighthouse CI (Core Web Vitals) | ✓ | ✓ | ✓ |
| Мониторинг latency (P50, P95, P99) | — | ✓ | ✓ |
| Мониторинг error rate | — | ✓ | ✓ |
| Мониторинг ресурсов (CPU, RAM, диск) | — | Выборочно | ✓ |
| APM на уровне приложения (Nightwatch / New Relic) | — | Выборочно | ✓ |
| Настраиваемые дашборды Grafana | — | — | ✓ |
| Проактивные уведомления о деградации | — | ✓ | ✓ |
| Error Budget tracking | — | — | ✓ |
| Отчётность по SLI | По запросу | Ежемесячно | Еженедельно + QBR |
| Целевой Uptime (SLO) | 99,5 % | 99,5–99,8 % | до 99,9 %* |
Модель критичности инцидентов
| Уровень | Описание | Первая реакция (SLO) | Восстановление (SLO) |
|---|---|---|---|
| S1 — Критический | Полная или частичная недоступность, заблокирован ключевой бизнес-процесс, инцидент безопасности | ≤ 20 мин (рабочие часы) | ≤ 4 часа |
| S2 — Высокое влияние | Существенная деградация с обходными путями, влияние на SEO или конверсию | ≤ 1 час | ≤ 8 часов |
| S3 — Среднее влияние | Дефекты с ограниченным влиянием на бизнес | ≤ 4 часа | В рамках спринта |
| S4 — Низкое влияние | Косметические проблемы, UX-улучшения | ≤ 1 рабочий день | По приоритету в бэклоге |
Прозрачность и отчётность
Что входит в отчёт по SLI
| Раздел | Содержание |
|---|---|
| Uptime за период | Фактический процент доступности в сравнении с целевым SLO |
| Latency-тренды | Динамика времени отклика (P50, P95) с выделением аномалий |
| Error rate | Процент ошибок с разбивкой по типам и источникам |
| Core Web Vitals | Динамика LCP, INP, CLS и влияние на SEO-позиции |
| Инциденты за период | Количество, критичность, время реакции и восстановления |
| Error Budget | Сколько бюджета израсходовано и сколько осталось |
| Рекомендации | Конкретные шаги по улучшению показателей |
Периодичность отчётности
| План | Отчёт по SLI | Формат |
|---|---|---|
| Basic | По запросу | Сводка в тикет-системе |
| Extended | Ежемесячно | PDF + комментарии |
| Enterprise | Еженедельно + ежеквартальный QBR | Дашборд + PDF + созвон |
Наш подход к надёжности
Границы ответственности и исключения
Наша зона ответственности
Зона ответственности заказчика
Что обычно не покрывается SLI
Конкретные границы ответственности и перечень исключений фиксируются в договоре и могут отличаться в зависимости от архитектуры проекта и выбранного плана поддержки.
